Getting Started with Python and PySPEDAS
Requirements
PySPEDAS supports Windows, macOS and Linux.
At this writing (October 2025), the core PySPEDAS features are compatible with Python versions 3.10 through 3.14. Some optional extras (for example, the basemap package used to render SECS/EICS data) may only be compatible through Python 3.13.
The following installation guide represents a somewhat minimal approach to getting a working PySPEDAS installation. It assumes you are starting from scratch, with no pre-existing Python version or developer tools installed. More advanced users might wish to make different choices of Python distributions (e.g. python.org rather than Anaconda), or use a different development environment (e.g Spyder, Visual Studio Code, or some other environment rather than PyCharm). The installation details might differ slightly for various operating systems or choices of Python distribution or development environment, but the general order of operations should be simple and straightforward.
Installing Python
You will need to install a compatible version of Python on your system (even if one is pre-installed with the operating system, it is not recommended to use it for PySPEDAS. There is no issue having multiple Python versions or installations on the same machine).
For managing Python environments to be used with PySPEDAS, we recommend Anaconda (https://www.anaconda.com/download), Anaconda gives you a relatively easy way to install and manage Python environments, and comes with a suite of packages useful for scientific data analysis. Step-by-step instructions for installing Anaconda can be found at: (Windows) (https://docs.anaconda.com/anaconda/install/windows/), (macOS)(https://docs.anaconda.com/anaconda/install/mac-os/), (Linux)(https://docs.anaconda.com/anaconda/install/linux/)
Anaconda is not a requirement – PySPEDAS will run just fine in a Python installation downloaded from python.org. However, Anaconda may make it easier to install some of the other Python packages PySPEDAS depends on. Some PySPEDAS dependencies are not always available as pre-compiled wheels, depending on the OS and CPU architecture you’re using. (Older releases of MacOS seem to be particularly prone to package installation issues). While a full Anaconda installation is larger and more complicated than downloading directly from python.org, it does have the advantage of allowing a user to “conda install” a dependency if “pip install” doesn’t work. Anaconda also has the advantage of bundling many other tools that are useful to scientific programmers.
As of October 2025, Python 3.14 is the latest available Python release. The core PySPEDAS features are all compatible with Python 3.14, but there are still compatibility issues with a few dependencies, particularly the basemap package used to create plots from SECS/EICS data. Since Python 3.14 has only been released a few weeks ago, it’s possible that the rest of the dependencies will catch up soon.
Python 3.13 is well-tested and fully compatible with PySPEDAS, but some users may want to avoid it because of poor performance for some workloads. Python 3.12 is a solid choice, performs better than Python 3.13, and is therefore the one we would recommend to most users.
To install Python using Anaconda, start “Anaconda Navigator”. You should see something like this:

Locate the “Environments” tab highlighted in the above screenshot, and click on it. The Environments screen should look something like this:
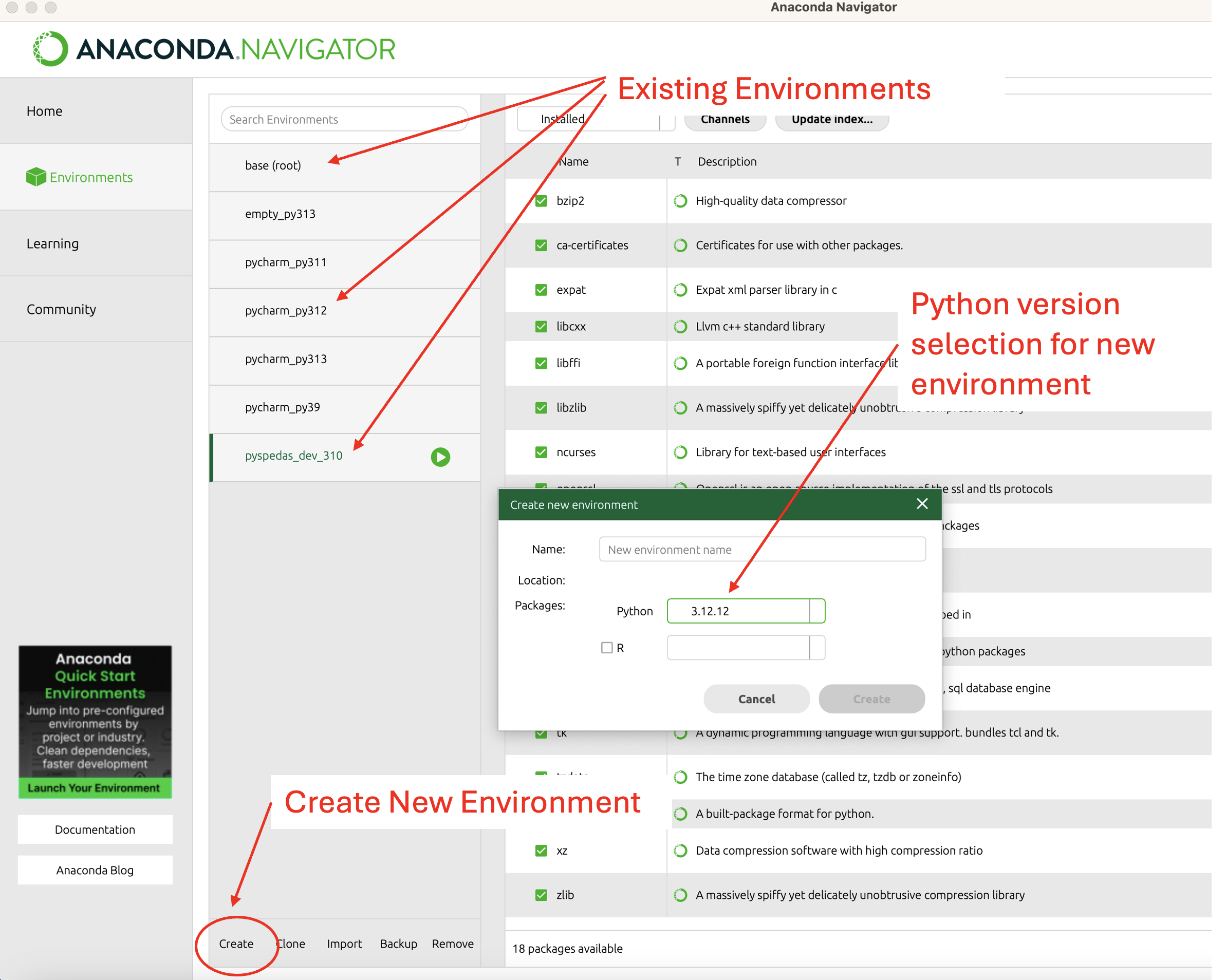
The center pane shows any Python environments that have already been created by Anaconda. To create a new Python environment, locate the ‘Create’ control highlighted in the above screenshot, and click it to bring up the “New Environment” dialog. Make sure the “Python” option is selected, and use the dropdown control to select the version of Python to be used in the new environment. Finally, enter the name you want to use for the new environment (perhaps something like ‘pyspedas_conda_py312’), and click “Create”. This should set up Anaconda will then start setting up a new Python environment for you to use with PySPEDAS.
Installing PyCharm
PyCharm is a free-to-use interactive development environment for Python. This (or whatever other IDE you prefer) is the main tool you will use to interact with Python and PySPEDAS.
The software can be downloaded and installed from https://www.jetbrains.com/pycharm/download/ .
After completing the download, click on the installer and follow the prompts. Near the end of the installation (depending on your operating system), you may come to a screen with some options: “64-bit launcher”, “Open folder as project”, “.py file associations”, “Add launchers dir to the PATH”. We recommend selecting all these options.
You may need to restart your machine to finalize the installation.
More PyCharm installation instructions are available at https://www.jetbrains.com/help/pycharm/installation-guide.html
Set PySPEDAS environment variables
By default, the data is stored in your pyspedas directory in a folder named ‘pydata’. This is probably not what you want.
The recommended way of setting your local data directory is to set the SPEDAS_DATA_DIR environment variable. SPEDAS_DATA_DIR acts as a root data directory for all missions, and will also be used by IDL (if you’re running a recent copy of the bleeding edge). If you already use IDL SPEDAS, and have SPEDAS_DATA_DIR set in your environment, no further action is needed.
You should set SPEDAS_DATA_DIR to a folder where you have write access, preferably on your hard drive rather than a network drive or mount point, on a filesystem which has enough free space to accomodate many gigabytes of downloaded data. It’s probably best to create that top-level folder by hand, if it doesn’t already exist. (Any needed subdirectories will be created automatically by SPEDAS or PySPEDAS). For example, you might use “C:\spedas_data” on Windows to put it at the root of your hard drive, or “/Users/your_userid/spedas_data” on a Mac to put it under your home directory.
Once you’ve decided where to put your data directory, you need to ensure that the SPEDAS_DATA_DIR environment variable is set whenever you log in. On Mac or Linux, this can be done by adding a line to your shell startup files (e.g. .cshrc, .zshrc, .bashrc or whatever shell you use):
setenv SPEDAS_DATA_DIR /path/to/data/directory
On Windows, you can open the Windows settings, search for “environment variables”, go to the appropriate control panel, and add the SPEDAS_DATA_DIR environment variable to your user environment variable settings.
You may need to log out of your account and log back in so these changes take effect.
Create a Python project in PyCharm
You will need to create a Python project within PyCharm, and connect it to the Python environment you previously set up with Conda.
You should have an icon for PyCharm on your desktop or start menu. Use it to open PyCharm.
Instructions for creating a new PyCharm project and environment can be found here: https://www.jetbrains.com/help/pycharm/creating-and-running-your-first-python-project.html
In PyCharm, use the File->New Project… menu to bring up a dialog that should look something like this:
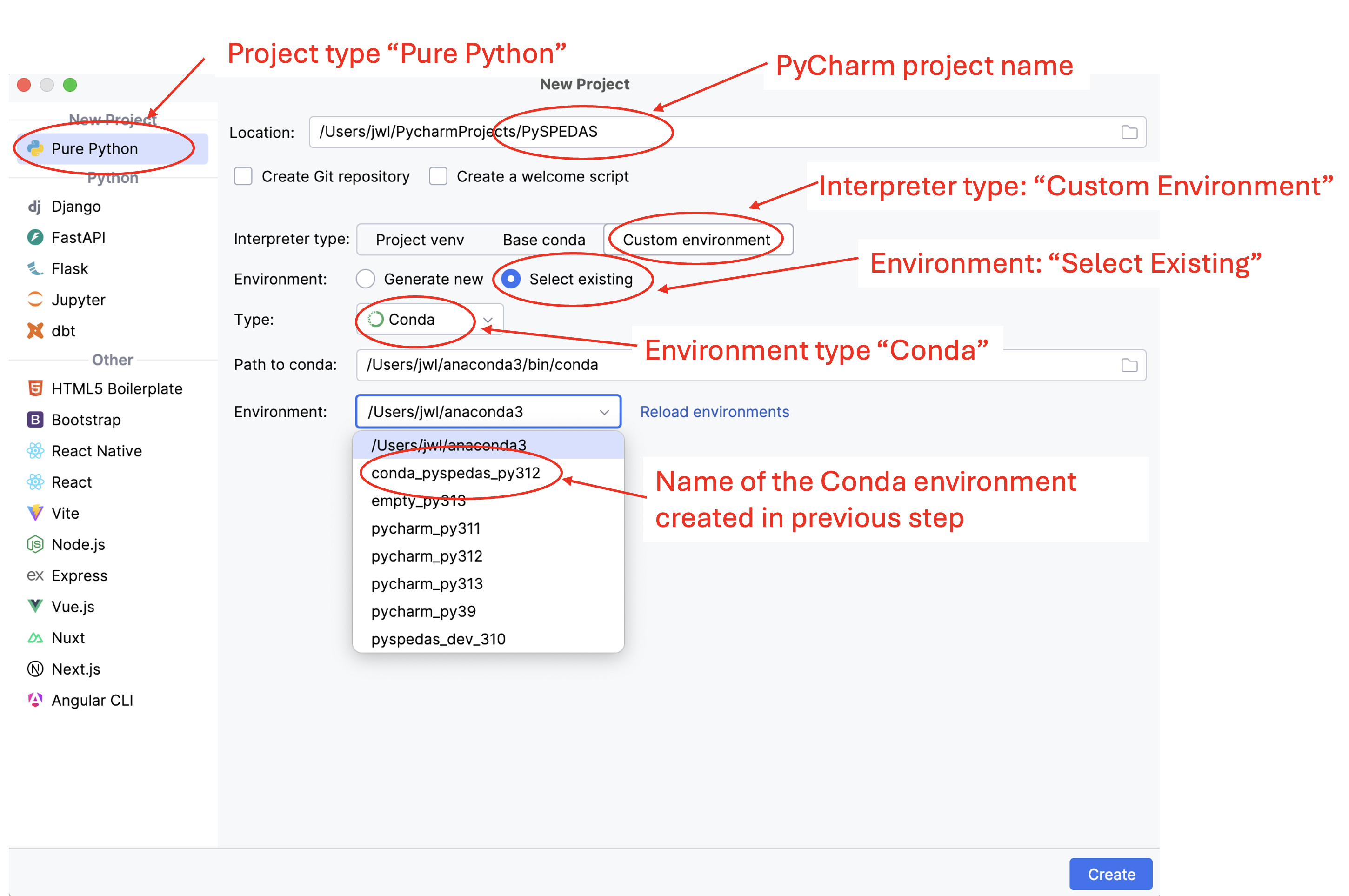
The above screenshot highlights the choices you should make in the “New Project” dialog: it should be created as a “Pure Python” project. Choose an appopriate name for your project (here, “PySPEDAS”). For “Interpreter Type”, select “Custom Environment”. For “Environment:” select “Select existing”. Use the “Type:” dropdown to select “Conda”. Use the “Environment:” dropdown menu to select the name of the Anaconda environment you set up in a previous step (here, we’re using “conda_pyspedas_py312).
When you’ve made all the necessary selections, click on the “Create” button in the lower right. PyCharm will set up your new PySPEDAS project, and connect it to the Python environment you created in Anaconda. This step may take several minutes, as it sets up a new Python virtual environment, copies the necessary files into it, and indexes them. At the bottom of your PyCharm window, there should be a status area and progress bar showing what it’s doing.
Location of PyCharm tools and menus
Here are the locations of a few controls and settings you’ll frequently use in PyCharm:

Show/Hide project files: This toggles whether the project files pane is displayed.
Project files: This pane shows the file and folder structure of your project.
Code editor: This is where you edit Python code. Each file is displayed in its own tab.
PyCharm and project settings: This is a way to change the settings for PyCharm generally, or specifically within a PyCharm project.
PyCharm tutorials: Opens a demo project and guides you through some common Pycharm tasks like editing and running code. Highly recommended!
Interactive Python window: This is where you can enter Python code line by line to see what it does.
Installed Python packages: This shows a list of Python packages installed in the project’s virtual environment, and indicates whether any updates are available.
Terminal window: This is an interactive command shell. The execution path will include files in the current project. This where you would run commands like “pip install” or “jupyter notebook”.
Program input/output area: When you select one of the tool windows from the lower left group of icons, this pane changes to show the input/output of that tool.
Check PyCharm setting for Python plots (PyCharm Professional version only)
If you are just using the base PyCharm installation, and have not paid for a PyCharm Professional license, you may skip this section: this feature is only available to PyCharm Professional users, and the settings described here don’t exist in the base version.
By default, PyCharm (Professional version) may display plots in its own interface. This is not what you want, because it doesn’t allow interactive usage like panning or zooming into a plot. Select the “Settings…” menu, then find “Tools” in the left hand pane and expand it. You should see something like this:
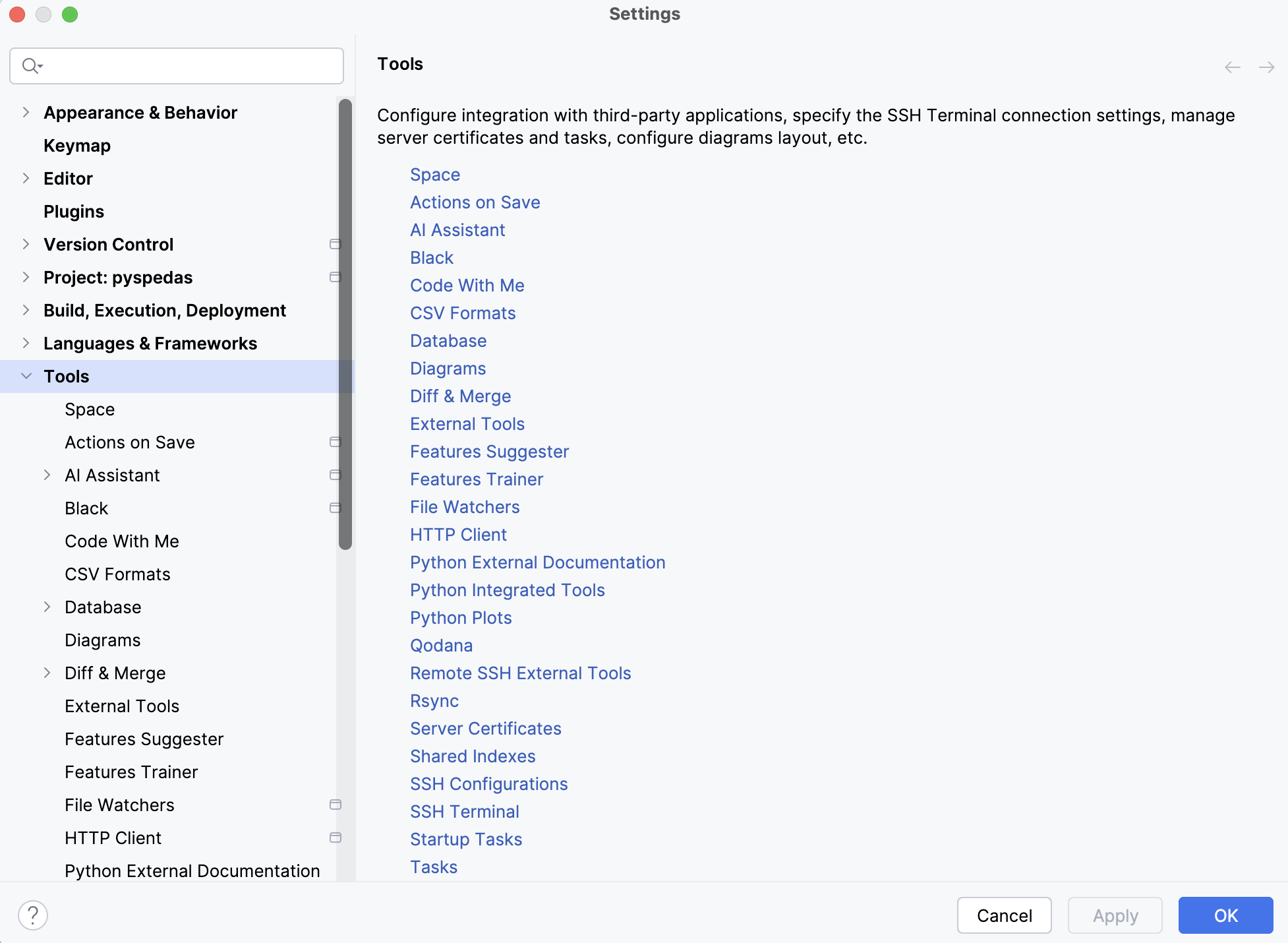
Scroll down until you find the “Python Plots” option and click on it.
You should see something like this:

The “Show plots in tool window” checkbox should be unchecked and the rest grayed out, as it appears in the above screen shot. If the box is checked, click on it to disable the option, then click “OK” to update the settings.
Try a simple PySPEDAS workflow
You should now be ready to run some code using PySPEDAS! Here’s a quick demo to try.
In the upper left pane of the PyCharm window, there should be a file tree showing the PyCharm project you’ve created (let’s say it was “pyspedas_project”. If it’s not showing, look for a “folder” icon in the upper left, and click on it.
Click on the “pyspedas_project” entry in the directory tree to select it. Then click on “File->New…” and choose “Python File” from the list of options. Name it “pyspedas_demo.py”. It should open in an editing pane in the upper left of the PyCharm window.
Now copy and paste this demo code into the editing pane:
# Load and plot THEMIS FGM data
def pyspedas_demo():
# Import pyspedas routines to be used
from pyspedas import tplot
from pyspedas.projects.themis import fgm
# Set the time range: 2007-03-23, complete day
trange=['2007-03-23' , '2007-03-24']
# Load THEMIS FGM data for probe A
fgm_vars = fgm(probe='a',trange=trange)
# Print the list of tplot variables just loaded
print(fgm_vars)
# Plot the 'tha_fgl_dsl' variable
tplot('tha_fgl_dsl')
# Run the example code
if __name__ == '__main__':
pyspedas_demo()
If all goes well you should see a green triangle just to the left of the “if __name__ == ‘__main’ line of code. (If not, look for any red squiggles indicating syntax errors or other issues in the demo program).
Click on the green triangle and select “Run pyspedas_demo”. This should run the example program, In the “Run” pane on the bottom half of the PyCharm window, you should see some output as pyspedas downloads THEMIS data, and prints the tplot variables loaded. A plot should appear, showing a plot for “tha_fgl_dsl”.
If you got this far, congratulations! You are now ready to write your own programs using PySPEDAS!
Working with Jupyter notebooks
PySPEDAS tutorial examples and sample workflows are often shared as Jupyter notebooks. This is a convenient format for sharing and teaching, because it allows intermingled rich text (explanations, sample plots, etc) and executable code cells. By breaking the workflow up into discrete steps, it’s easy to make changes and rerun a single cells to see updated output, or add additional Python commands to print or plot values of intermediate results.
Jupyter notebooks are stored as files with extension “.ipynb” (for Interactive PYthon NoteBook). They run in a browser window, which allows you to run the entire notebook at once, or step through cell by cell, inspecting intermediate results, or modifying the code to see what happens.
The Google Colab service allows you to run a Jupyter notebook completely in their cloud environment, with no local Python or PySPEDAS installation required. However, for this guide, we will show how to run a notebook within your PyCharm project.
Let’s say someone has sent you a notebook as an email attachment (with file extension .ipynb), or as a web link. Since we have several GitHub repositories full of PySPEDAS example notebooks, we’ll show how to download and run one of those. Try opening this URL:
You should see something like this:
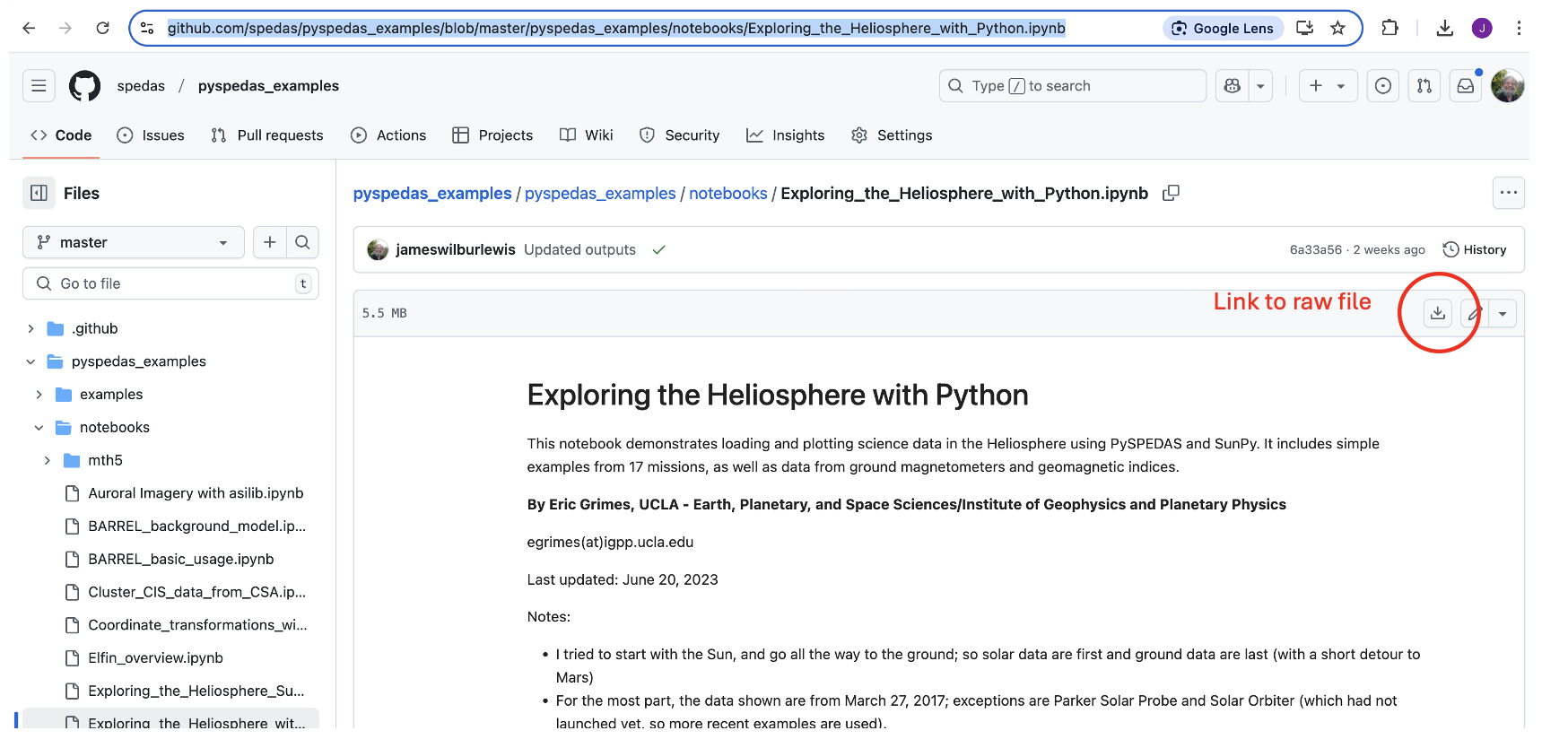
You would not want to “Save as…” this page in your browser, because that would save the HTML rendering, and not the actual notebook code. Instead, find the control highighted in the above image, and click it to download the raw ipynb file. Then find the file you just downloaded, and copy it into the top level “PySPEDAS” directory that contains your PyCharm project.
Next, you’ll want to open the “Terminal” window (not the interactive Python window….see the earlier PyCharm screen shot to locate the correct control). You should have previously installed the “jupyter” Python package when you set up the project. You can open the notebook with the command
jupyter notebook Exploring_the_Heliosphere_with_Python.ipynb
(If you omit the filename and just do “jupyter notebook”, you will get a list of whatever notebooks are in your project, and you can click on the one you want to run).
You may be prompted to select a kernel (the Python installation to be used when runnng your notebook). If so, select the default kernel and continue.
This will open a browser window (or open a new tab in your existing browser) which should look something like this:

A few frequently-used controls are highlighed in red:
File menu: Save changes to your notebook, open a new notebook, etc
Add new cell: Add a new Markdown or code cell below your current location in the notebook
Run current cell: Renders the Markdown code, or runs the Python code in the current cell, and advances to the next cell.
Run all cells in notebook: Run the entire notebook from start to finish.
To get started with the notebook you’ve just opened, I’d suggest clicking the “Run current cell” control to step through the notebook cell-by-cell and see what happens at each step.
For more information, you might want to check out the official documentation: https://jupyter-notebook.readthedocs.io/en/latest/notebook.html
PySPEDAS Example Notebooks
The PySPEDAS team maintains several GitHub repositories containing Jupyter notebooks showing many different examples of how to use PySPEDAS for loading, analyzing, and plotting heliophysics data.
At this time we offer three repositories of PySPEDAS examples:
Basic PySPEDAS usage and simple workflows: https://github.com/spedas/pyspedas_examples/blob/master/pyspedas_examples/
Simple workflows using THEMIS data: https://github.com/spedas/themis-examples/blob/master/themis-examples/
Workflows (beginning through somewhat advanced) using MMS data: https://github.com/spedas/mms-examples/blob/master/mms-examples
To use them, go to one of the URLs above, find a notebook you’re interested it, then use the steps described in the previous section to download the notebook and run it in your own PySPEDAS environment.
PySPEDAS Examples on Google Colab (PySPEDAS in the cloud: no local installation required!)
Google’s Colab service offers a cloud environment that is capable of running Jupyter notebooks. This is a good option if you want to try PySPEDAS without worrying about installing it locally, or if you want to share a workflow with a colleague who may not have PySPEDAS installed.
Google Colab has a built-in capability to run Jupyter notebooks directly from a GitHub repository.
To run a PySPEDAS notebook from one of our example repositories in Google Colab:
Open your browser to https://colab.research.google.com/ .
From that page, you should be able to select “GitHub” from the left hand pane, then enter the Github organization ‘spedas’ in the search box. This will bring up a list of repositories associated with SPEDAS, as shown in the image below:

Scroll through the list of SPEDAS repositories, find the examples you’re interested in running (pyspedas_examples, themis-examples, or mms-examples), and click on that entry. The screenshot below shows the list of notebooks available if you select the pyspedas_examples repository:
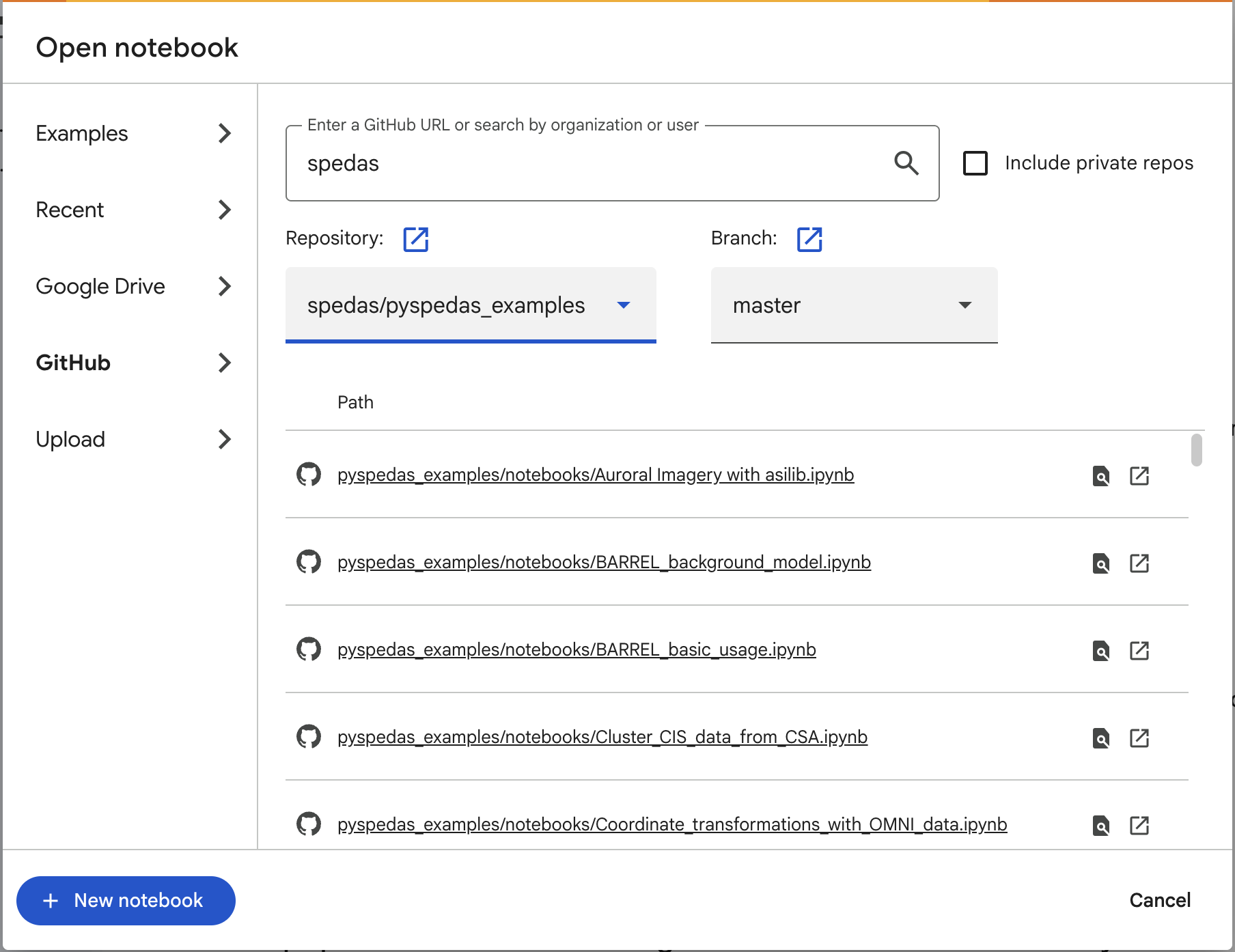
The next screen will show a list of available notebooks from that repository. Find one that you’re interested in, and click on it – that should bring up an interactive Jupyter session with that notebook loaded:

All the PySPEDAS example notebooks are designed to be runnable on Google Colab. In the above image, you can see that the first code cell in the notebook contains a command to install PySPEDAS:
!pip install pyspedas
PySPEDAS wouldn’t normally be installed in a fresh Google Colab environment, so this line is included to let you install pyspedas (in Google’s cloud environment) without leaving the notebook. You may skip this line if you’ve downloaded the notebook and are running it in an environment that already has PySPEDAS installed.
Creating Jupyter notebooks
The Jupyter notebook interface also allows you to create your own notebooks. From a terminal window, start the Jupyter server:
jupyter notebook
Accept the default kernel if prompted, then go to the browser window that Jupyter should have opened. You will see that the Jupyter browser page has its own “File” menu. Select File->New->Notebook . This should open another browser tab or window with an empty notebook you can edit. To save it, from that notebook’s browser window, use the Jupyter File menu to select File->Save As (if you haven’t named the notebook yet), or File->Save (if you’ve already named it via Save As, and are just saving incremental changes.